

For Research Nerds: clipping information and making it OCR searchable
When I’m researching and I see a bit of text relevant to my WIP (either online or on Kindle), I will clip it: shift-command-4 and “pull” rectangle around the text I want.
It’s so easy to do I often end up with a mess on my computer desktop. Here’s a screen shot to give you an idea how things can look at the end of a day:
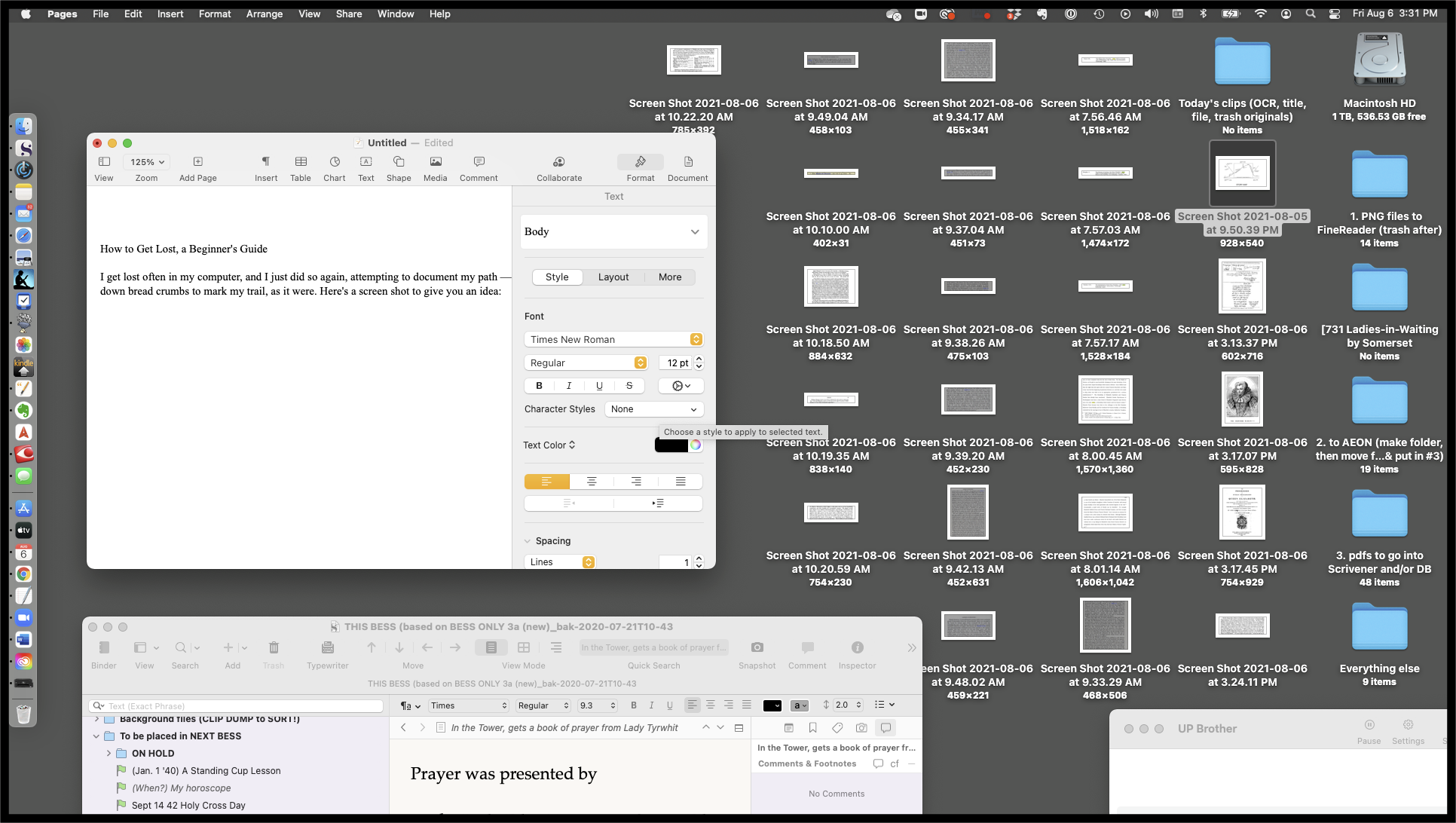
My next step is to gather up all the clips and drag them into an empty “Today’s clips” folder. That, at least, looks manageable.
Why it’s important to a researcher for all files to be searchable
Research clips are not of much use to me unless I can search the text. For example, if I was looking for clips about Mother of the Maids I should be able to search that title and all relevant files would be listed.
Clips are a png file, a type of photo, so how is this done?
For the text in a photo to be searchable it needs to have OCR — optical character recognition. Basically, OCR makes it possible to search for a word in a photo. Magic.
I’ve messed around with OCR software quite a bit over time. Software such as OneNote claims to convert files automatically, but sometimes so very slowly it’s not practical. Evernote can be touchy and deliver poor results. Also, I need to be able to easily move the OCR’d clip into my writing programmes (Scrivener and AEON Timeline, at this time), which I can’t do — at least not easily — out of Evernote or OneNote.
Why not send a clip directly to Scrivener?
One of the strengths of Scrivener is that I can clip a bit of text from a website directly into my project. However, Scrivener does not offer OCR (at least at this time), so while I will often post a web address URL to Scrivener, I won’t send a clip. I need to be able to search the text of a clip, and without OCR, I can’t do that.
ABBYY FineReader software to the rescue
FineReader is simply an awesome OCR software: fast, powerful and reliable, but at around $150 for Mac, it’s not cheap. (There is a 2-week free trial offered, however.) (Check: is it subscription for Pro?)
I’ll show you what FineReader does with a day’s pile of clips:
I select and drag all of them into the Fine Reader icon in the dock:
![]()
It bounces around a bit as it does the work, and then, snap, it’s done.
FineReader, step-by-step
First I get a “Completed” notice with problem alerts — these I simply ignore and click “Close.”
The next screen shows small images of the clips on the left with enlarged versions on the right. I also ignore all that and click “Export” in the header.
That brings me to this window, which has the PDF option lightly highlighted. I ignore all the options in the middle and click Next in the lower right corner.
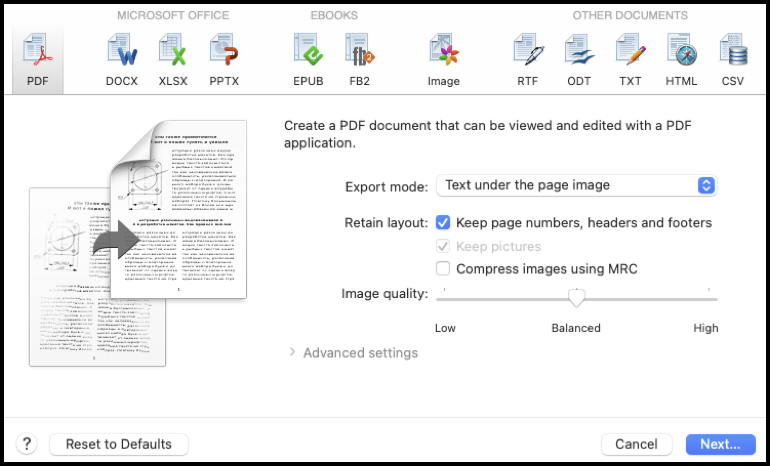
The final window gives me the opportunity to name the collection. I type in “Today’s clips” and select where I want them to show up on my computer (desktop, for now).
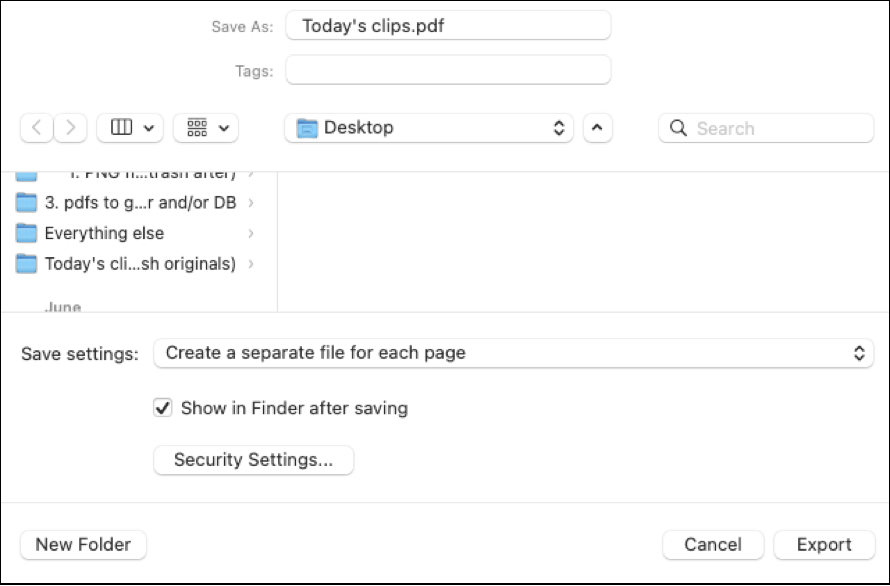
Caution!
The really, really, really important thing about this final window is to save each clip to a separate file. (Unless it’s a book file: You don’t want a separate file for each page!)
![]()
Click “Export,” and it’s done.
Done? Almost …
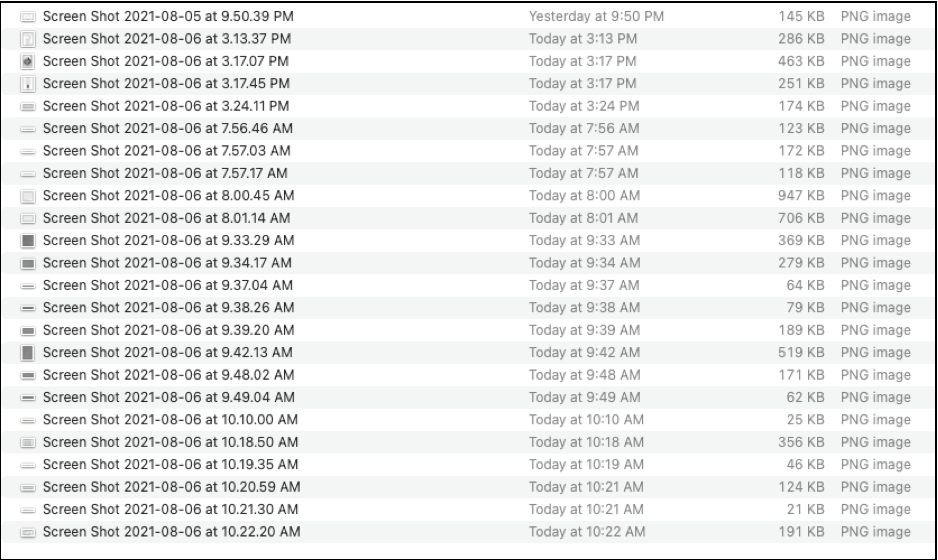
I now have 24 searchable clips which I rename and file to put into either AEON Timeline (for events and date-specific clips) or my Scrivener project file. I then trash the original unsearchable clips.
I do a computer search for “Mother of the Maids” and of the over 20 pdf files listed, my 3 newest clips that mention “Mother of the Maids” are listed at the top:

Success!
And that’s it, for now. Next up, I hope to write a blog post about Mrs. Stonor (sometimes Stoner), a Mother of the Maids who looked after the young, unmarried Maids of Honour who served most if not all of Henry VIII’s six wives. Four of these maids became the next wife and all four ended up dead.
Now there’s a story. :-)
After not using FineReader for a time, the documents would not come out searchable. I messed with this for hours without luck — until I clicked the “set to default” button in the last frame. :-)
The one problematic part of this process is that the file will come out “untitled,” so I select and copy the title before putting it through the process.
